A significant challenge for companies using the cloud lies in ensuring that
their firewall rules follow the principle of least privilege. It is
extremely common nowadays to delegate management of security groups to developers, for
both production and test environments. This means that security groups and
their associated rules are managed by a much larger number of employees than
what used to be the case in non-cloud environments, where a unique, smaller
team was in charge of managing all firewall rules. Due to the more dynamic
nature of cloud-based infrastructures, companies should review their cloud
environment's firewall rules on a more frequent basis than for non cloud-based
systems. Unfortunately, this is a difficult exercise due to the large number of
CIDRs that may be whitelisted in a given AWS account. Keeping track of all
known CIDRs and what hosts or networks they represent is not easy for
employees, and is almost impossible for external auditors who must perform the
review within a limited timeframe.
In this post, I will document how this issue can be addressed using the
AWS-Recipes tools and
Scout2.
Feed custom ip-ranges files to Scout2
Today, I am excited to announce that Scout2 accepts JSON files that
contain known CIDRs along with arbitrary metadata such as the host or network
they represent. When provided with such files, Scout2's report displays the
"friendly name" of each known CIDR that is whitelisted in security group rules.
This means that, instead of reviewing a list of obscure IP ranges, users of
Scout2 may now rely on the name associated with each CIDR.
In order to use this new feature, Scout2 should be run with the following
arguments:
./Scout2.py --profile nccgroup --ip-ranges ip-ranges-nccgroup.json ip-ranges-ncc-offices.json --ip-ranges-key-name name
In the above command line, Scout2 receives two ip-ranges JSON files via the
"--ip-ranges" argument:
- ip-ranges-nccgroup.json, which contains the public IP addresses in the AWS IP space in use
- ip-ranges-ncc-offices.json, which contains the public IP addresses of several offices
Furthermore, the "--ip-ranges-key-name" argument indicates which JSON field to
display as the "friendly name".
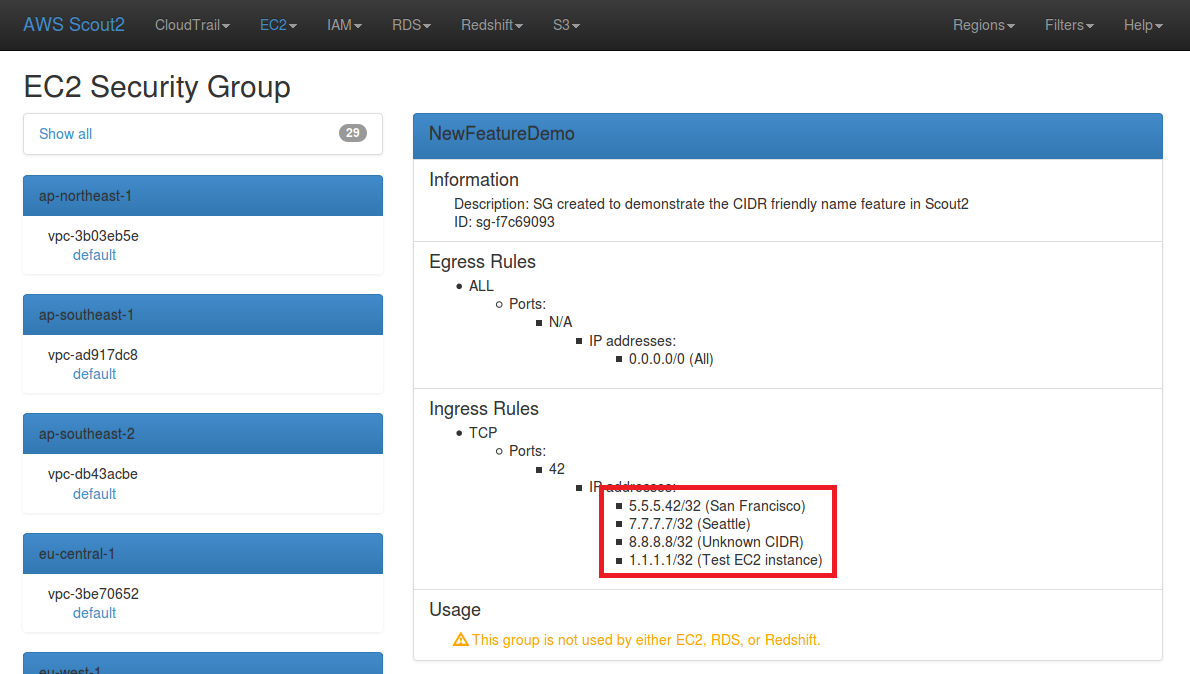
The following screenshot illustrates that, in the Scout2 report, the name of
each known CIDR is displayed. When an IP which belongs to a known CIDR is
whitelisted, the name of the corresponding CIDR is used. In this example,
5.5.5.42/32 belongs to the 5.5.5.0/24 CIDR, which is associated with the "San
Francisco" office. An "Unknown CIDR" value is displayed when an unknown value
is whitelisted.
The next section of this blog post documents how users can create and manage
these ip-ranges JSON files.
Manage known CIDRs with aws_recipes_create_ip_ranges.py
With AWS releasing their public IP address ranges, I decided to create a tool
that allows creation and management of arbitrary IP address ranges using the
same JSON format. The tool is released on GitHub at
https://github.com/iSECPartners/AWS-recipes/blob/master/Python/aws_recipes_create_ip_ranges.py
and may be used in several scenarios:
- Automatically create ip-ranges files based on public IP addresses in AWS (Elastic IPs and EC2 instances)
- Automatically create ip-ranges files based on IP addresses documented in a CSV file
- Manually create and manage ip-ranges files
Each of these use cases is detailed in an example below, with detailed input,
commands, and output contents.
Note: In the commands below, the "--debug" argument is used to
output pretty-printed JSON, for documentation purposes.
Automatically create ip-ranges based on public IP addresses in an AWS account
First, this tool may be used to create an ip-ranges file that contains an AWS
account's elastic IP addresses and EC2 instances' public IP addresses. By doing
so, AWS users will be able to maintain a list of public IP addresses in the AWS
IP space that are associated with their resources. Assuming that AWS
credentials are configured under the "nccgroup" profile name, the command
below may be used:
$ ./aws_recipes_create_ip_ranges.py --profile nccgroup --debug
Fetching public IP information for the 'nccgroup' environment...
...in us-east-1: EC2 instances
...in us-east-1: Elastic IP addresses
...in ap-northeast-1: EC2 instances
...in ap-northeast-1: Elastic IP addresses
...in eu-west-1: EC2 instances
...in eu-west-1: Elastic IP addresses
...in ap-southeast-1: EC2 instances
...in ap-southeast-1: Elastic IP addresses
...in ap-southeast-2: EC2 instances
...in ap-southeast-2: Elastic IP addresses
...in us-west-2: EC2 instances
...in us-west-2: Elastic IP addresses
...in us-west-1: EC2 instances
...in us-west-1: Elastic IP addresses
...in eu-central-1: EC2 instances
...in eu-central-1: Elastic IP addresses
...in sa-east-1: EC2 instances
...in sa-east-1: Elastic IP addresses
My test environment has one elastic IP address that is not associated
with an AWS resource, and one EC2 instance that has a non-elastic public IP.
Executing the above command results in the creation of an
"ip-ranges-nccgroup.json" file that has the following contents:
{
"createDate": "2015-11-16-22-49-27",
"prefixes": [
{
"instance_id": "i-11223344",
"ip_prefix": "1.1.1.1",
"is_elastic": false,
"name": "Test EC2 instance",
"region": "us-west-2"
},
{
"instance_id": null,
"ip_prefix": "2.2.2.2",
"is_elastic": true,
"name": null,
"region": "us-west-2"
}
]
}
Automatically create ip-ranges from CSV files
From experience, I know that many companies maintain a list of their
public IP addresses, along with other network configuration information, in alternate formats, such as CSV. In
order to help with the conversion, the tool supports reading CIDR information
from CSV files. The tool was designed to be flexible and allow the creation of IP
ranges from any CSV file. In this blog post, I provide two examples.
This first example demonstrates how to use the tool to build a JSON file based
on the CSV column headers. Only attributes specified on the command line will
be copied over.
Contents of test1.csv:
ip_prefix, discarded_value, name
4.4.4.0/24, ncc group, NY office
# This is a comment...
5.5.5.0/24, ncc group, Seattle office
Command line to convert the contents of the CSV file into JSON:
./aws_recipes_create_ip_ranges.py --csv-ip-ranges test1.csv --attributes ip_prefix name --profile ncc-test1 --debug
Contents of ip-ranges-ncc-test1.json:
{
"createDate": "2015-11-17-10-22-42",
"prefixes": [
{
"ip_prefix": "4.4.4.0/24",
"name": " NY office"
},
{
"ip_prefix": "5.5.5.0/24",
"name": " Seattle office"
}
]
}
The second example demonstrates how to use the tool to parse a CSV file with
custom column names and separate columns for the base IP and subnet mask. The
"--mappings" argument determines how columns will be mapped to the JSON
file's attributes.
Contents of test2.csv
Base IP, Dotted Subnet Mask, Subnet Mask, Something, Name, Something else
3.3.3.0, 255.255.255.0, /24, Value to discard, SF Office, Other value to discard
Command line to convert the contents of the CSV file into JSON:
./aws_recipes_create_ip_ranges.py --csv-ip-ranges test2.csv --attributes ip_prefix mask name --mappings 0 2 4 --profile ncc-test2 --skip-first-line --debug
Contents of ip-ranges-ncc-test2.json
{
"createDate": "2015-11-17-10-07-22",
"prefixes": [
{
"ip_prefix": "3.3.3.0/24",
"name": " SF Office"
}
]
}
Manually create and update ip-ranges
In case CIDRs were not managed in a CSV file, the tools offers an interactive
mode that may be leveraged to manually create a JSON ip-ranges file. The
following snippet illustrates how to use the tool to interactively create new
ip-ranges JSON files:
$ ./aws_recipes_create_ip_ranges.py --interactive --profile ncc-offices --attributes name
Add a new IP prefix to the ip ranges (y/n)?
y
Enter the new IP prefix:
5.5.5.0/24
You entered "5.5.5.0/24". Is that correct (y/n)?
y
Enter the 'name' value:
San Francisco
You entered "San Francisco". Is that correct (y/n)?
y
Add a new IP prefix to the ip ranges (y/n)?
y
Enter the new IP prefix:
6.6.6.6/32
You entered "6.6.6.6/32". Is that correct (y/n)?
y
Enter the 'name' value:
San Francisco
You entered "San Francisco". Is that correct (y/n)?
y
Add a new IP prefix to the ip ranges (y/n)?
n
Contents of ip-ranges-ncc-offices.json:
{
"createDate": "2015-11-16-22-44-38",
"prefixes": [
{
"ip_prefix": "5.5.5.0/24",
"name": "San Francisco"
},
{
"ip_prefix": "6.6.6.6/32",
"name": "San Francisco"
}
]
}
The tool can also automatically add new CIDRs to existing ip-ranges files:
$ ./aws_recipes_create_ip_ranges.py --interactive --profile ncc-offices --attributes name --debug
Loading existing IP ranges from ip-ranges-ncc-offices.json
Add a new IP prefix to the ip ranges (y/n)?
y
Enter the new IP prefix:
7.7.7.7/32
You entered "7.7.7.7/32". Is that correct (y/n)?
y
Enter the 'name' value:
Seattle
You entered "Seattle". Is that correct (y/n)?
y
Add a new IP prefix to the ip ranges (y/n)?
n
File 'ip-ranges-ncc-offices.json' already exists. Do you want to overwrite it (y/n)?
y
$ cat ip-ranges-ncc-offices.json
{
"createDate": "2015-11-16-22-44-38",
"prefixes": [
{
"ip_prefix": "5.5.5.0/24",
"name": "San Francisco"
},
{
"ip_prefix": "6.6.6.6/32",
"name": "San Francisco"
},
{
"ip_prefix": "7.7.7.7/32",
"name": "Seattle"
}
]
}
Conclusion
This addition to Scout2 provides AWS account administrators and auditors with
an improved insight into their environment. Usage of this feature should result
in further hardened security groups because detection of unknown whitelisted
CIDRs and understanding of existing rules is significantly easier.
I am currently working on a major rework of Scout2's reporting engine,
which will further improve reporting and allow creation of new alerts when an
unknown CIDR is whitelisted.